Open Access to the Universe:the Largest and Most Sophisticated Cosmological Simulation is Now in Open Access Domain
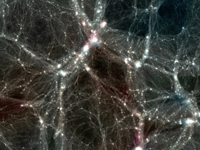
A small team of astrophysicists and computer scientists have created some of the highest-resolution snapshots yet of a cyber version of our own cosmos. The data which is a result of one of the largest and most sophisticated cosmological simulations is now open to public. People can observe it and researchers can use it to develop their theories and conduct varies kind of astrological and cosmological researches.
………………………………………………………………………………..
A small team of astrophysicists and computer scientists have created some of the highest-resolution snapshots yet of a cyber version of our own cosmos. Called the Dark Sky Simulations, they’re among a handful of recent simulations that use more than 1 trillion virtual particles as stand-ins for all the dark matter that scientists think our universe contains.
They’re also the first trillion-particle simulations to be made publicly available, not only to other astrophysicists and cosmologists to use for their own research, but to everyone. The Dark Sky Simulations can now be accessed through a visualization program in coLaboratory, a newly announced tool created by Google and Project Jupyter that allows multiple people to analyze data at the same time.
To make such a giant simulation, the collaboration needed time on a supercomputer. Despite fierce competition, the group won 80 million computing hours on Oak Ridge National Laboratory’s Titan through the Department of Energy’s 2014 INCITE program.
In mid-April, the group turned Titan loose. For more than 33 hours, they used two-thirds of one of the world’s largest and fastest supercomputers to direct a trillion virtual particles to follow the laws of gravity as translated to computer code, set in a universe that expanded the way cosmologists believe ours has for the past 13.7 billion years.
“This simulation ran continuously for almost two days, and then it was done,” says Michael Warren, a scientist in the Theoretical Astrophysics Group at Los Alamos National Laboratory. Warren has been working on the code underlying the simulations for two decades. “I haven’t worked that hard since I was a grad student.”
Back in his grad school days, Warren says, simulations with millions of particles were considered cutting-edge. But as computing power has increased, particle counts did too. “They were doubling every 18 months. We essentially kept pace with Moore’s Law.”
When planning such a simulation, scientists make two primary choices: the volume of space to simulate and the number of particles to use. The more particles added to a given volume, the smaller the objects that can be simulated-but the more processing power needed to do it.
Current galaxy surveys such as the Dark Energy Survey are mapping out large volumes of space but also discovering small objects. The under-construction Large Synoptic Survey Telescope “ill map half the sky and can detect a galaxy like our own up to 7 billion years in the past,” says Risa Wechsler, Skillman’s colleague at KIPAC who also worked on the simulation. “We wanted to create a simulation that a survey like LSST would be able to compare their observations against.”
The time the group was awarded on Titan made it possible for them to run something of a Goldilocks simulation, says Sam Skillman, a postdoctoral researcher with the Kavli Institute for Particle Astrophysics and Cosmology, a joint institute of Stanford and SLAC National Accelerator Laboratory. “We could model a very large volume of the universe, but still have enough resolution to follow the growth of clusters of galaxies.”
The end result of the mid-April run was 500 trillion bytes of simulation data. Then it was time for the team to fulfill the second half of their proposal: They had to give it away.
They started with 55 trillion bytes: Skillman, Warren and Matt Turk of the National Center for Supercomputing Applications spent the next 10 weeks building a way for researchers to identify just the interesting bits-no pun intended-and use them for further study, all through the Web.
“The main goal was to create a cutting-edge data set that’s easily accessed by observers and theorists,” says Daniel Holz from the University of Chicago. He and Paul Sutter of the Paris Institute of Astrophysics, helped to ensure the simulation was based on the latest astrophysical data. “We wanted to make sure anyone can access this data-data from one of the largest and most sophisticated cosmological simulations ever run-via their laptop.”
Source Symmetrymagazine
Related Post


